# 负载均衡 Nginx 的使用
该部分从属于数据采集部分,主要作用为实现几台数采服务器的负载均衡,因涉及新的技术 ---Nginx,所以单独成为一个 part

# 1.1 Nginx 概述
Nginx 是一个高性能的 HTTP 和反向代理服务器,特点是占有内存少,并发能力强
- 与 tomcat 的关系
除了 tomcat 以外, apache,nginx,jboss,jetty 等都是 http 服务器。
nginx 和 apache 只支持静态页面和 CGI 协议的动态语言,比如 perl 、 php 等, 但是 nginx 不支持 java 。
Java 程序只能通过与 tomcat 配合完成。 nginx 与 tomcat 配合,为 tomcat 集群提供反向代理服务、负载均衡等服务
# 1.1.1 Nginx 三大功能
# 反向代理
- 正向代理
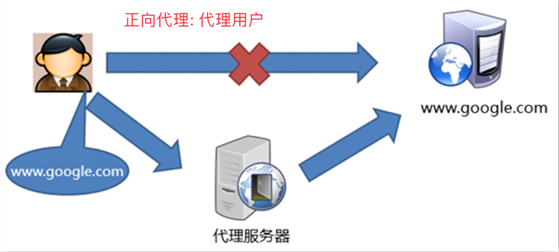
服务器代理用户的请求,从用户的角度看,没法直接获取请求,需要通过代理
特点:代理用户,用户清楚知道访问哪台服务器
- 反向代理
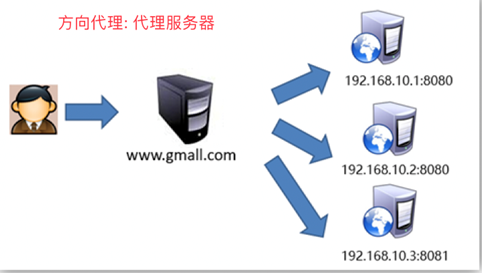
反向代理:服务器代理真正服务器,用户不确定去哪台真实服务器,
# 负载均衡
・轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某台服务器宕机,则自动剔除故障机器,使用户访问不受影响
・weight 指定轮询权重,weight 值越大,分配到的几率就越高,主要用于后端每台服务器性能不均衡的情况。
・备机模式 平时不工作,只有其他 down 机的时候才会开始工作
・公平模式 (第三方) 更智能的一个负载均衡算法,此算法可以根据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配。如果想要使用此调度算法,需要 Nginx 的 upstream_fair 模块。
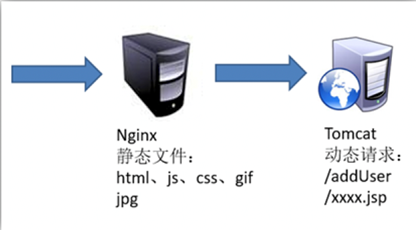
# 动静分离
# 1.2 Nginx 安装
- yum 安装依赖包
sudo yum -y install openssl openssl-devel pcre pcre-devel zlib zlib-devel gcc gcc-c++ |
- 下载 Nginx
/opt/software » wget http://nginx.org/download/nginx-1.12.2.tar.gz |
- 解压
tar -zxvf nginx-1.12.2.tar.gz -C /opt/module |
- 编译和安装
进入解压缩的目录
为了防止出现权限问题,建议切换到 root 用户
./configure --prefix=/usr/local/webserver/nginx | |
make && make install |
- 启停 Nginx
进入目录: /usr/local/webserver/nginx
启动 nginx: sbin/nginx | |
关闭 nginx: sbin/nginx -s stop | |
重新加载: sbin/nginx -s reload |
注意:
- Nginx 默认使用的是 80 端口,由于非 root 用户不能使用 1024 以内的端口,所以建议使用 root 用户启动 Nginx
- 如果使用普通用户启动 Nginx, 需要先执行下面的命令来突破上面的限制:
sudo setcap cap_net_bind_service=+eip /usr/local/webserver/nginx
- 查看 Nginx 进程
通过网页访问: http://hadoop109
# 1.3 配置负载均衡
# 1.3.1 Nginx 配置修改
- 修改 /usr/local/webserver/nginx/conf/nginx.conf
http { | |
..... | |
# 配置上游服务器:其实就被代理的服务器,springboot | |
upstream logserver{ | |
server hadoop109:8081 weight=1; | |
server hadoop110:8081 weight=1; | |
server hadoop111:8081 weight=1; | |
} | |
server { | |
listen 80; | |
server_name logserver; | |
location / { | |
root html; | |
index index.html index.htm; | |
# 配置代理 | |
proxy_pass http://logserver; | |
proxy_connect_timeout 10; | |
} | |
... | |
} | |
} |
Q:为什么不配置日志服务器端口为 8080
在 kafka 启动消费数据前要先打开 zookeeper 集群,在 zookeeper3.5.0 之后的版本中,集群打开后会默认占用 8080 端口
13317 Jps13229 QuorumPeerMain(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)通过观察日志可以发现确实启动了一个叫 adminServer 的服务
这是一个内嵌的 jetty 服务。如果想在 zookeeper 上解决这个问题,有以下三种方法

# 1.3.2 日志采集服务器群起脚本制作
分别在 3 个节点启动 jar 比较麻烦,制作统一启动脚本.
#!/bin/bashcase $1 in "start") { for i in hadoop201 hadoop202 hadoop203 do echo "========启动日志服务: $i===============" ssh $i "source /etc/profile ; java -jar /opt/module/gmall/gmall-logger-1.0-SNAPSHOT.jar >/dev/null 2>&1 &" done };; "stop") { for i in hadoop201 hadoop202 hadoop203 do echo "========关闭日志服务: $i===============" ssh $i "ps -ef|grep gmall-logger-1.0-SNAPSHOT.jar | grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1 done };; *) { echo 启动姿势不对, 请使用参数 start 启动日志服务, 使用参数 stop 停止服务 };;esac |
# 1.3.3 其他操作
- 分发启动采集服务器 jar 包到其余设备
- 给编写好的脚本增加执行权限
- 启动 Nginx
- 启动脚本
脚本编写的注意事项:
如果在 windows 环境下编写脚本后复制到 linux 系统中出现如下报错:
bad interpreter:/bin/bash^M: no such file or directory是因为在 window 下写的脚本回车的时候使用的是 \r\n, 而在 linux 使用 \n 就可以了,所在每行的末尾多了一个 \r.
使用下面的命令去掉行尾的 \r:
sed -i -e 's/\r$//' gmall_cluster
- 测试日志生成能否在集群中生成落盘日志与控制台打印