# 一、写 flume 的步骤
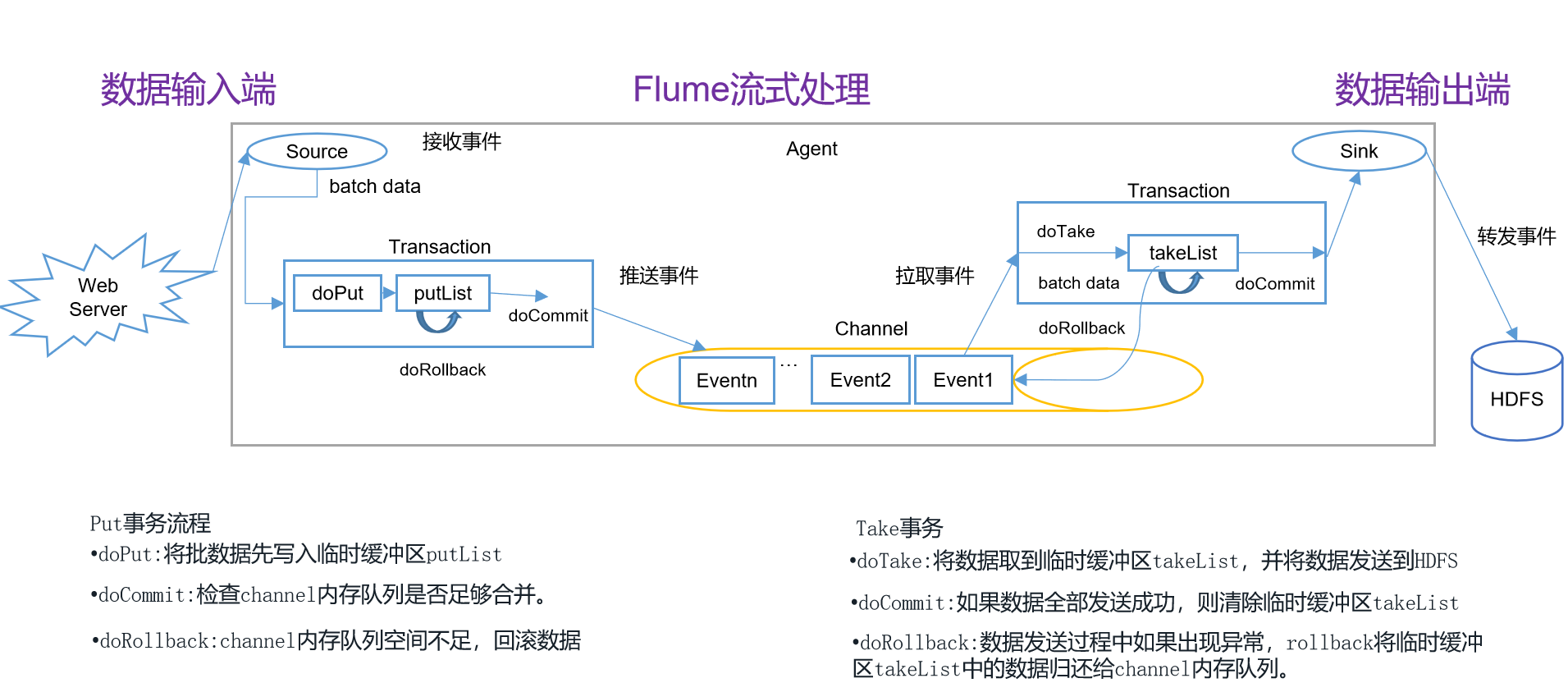
# 1.0.0 Flume 事务
![image-flume-事务]()
# 1.1 画拓扑图
总结:一个 channel 只能输出一个结果文件。
一个 flume agent 由 source + channel + sink 构成,类比于 mapper + shuffer + reducer。
# 1.1.1 确定 source 类型
| 常用类型: |
| 1) arvo: 用于Flume agent 之间的数据源传递 |
| 2) netcat: 用于监听端口 |
| 3)exec: 用于执行linux中的操作指令 |
| 4) spooldir: 用于监视文件或目录 |
| 5) taildir: 用于监视文件或目录,同时支持追加的监听 |
| 总结 ,3/4/5三种方式,最常用的是5,适合用于监听多个实时追加的文件,并且能够实现断点续传。 |
# 1.1.2 确定 channel selector 的选择器
| 1)replicating channel selector:复制,每个channel发一份数据 |
| 2) multiplexing channel selector : 根据配置配件,指定source源获取的数据发往一个或多个channel |
# 1.1.3 确认 channel 类型参数
| 1) Memory Channel : 加载在内存中,存在数据丢失的风险 |
| 2) File Channel :落入磁盘 |
# 1.1.4 确定 sinkprocessor 参数
| 1) DefaultSinkProcessor:对应的是单个的Sink |
| 2) LoadBalancingSinkProcessor :对应的是多个的Sink,可以实现负载均衡的功能 |
| 3) FailoverSinkProcessor :对应的是多个的Sink,容错功能,先指定一个sink,所有的数据都走指定的sink,当sink故障以后,其他的sink顶上,如果开始sink恢复了,那么数据继续走原有指定的sink。 |
# 1.1.5 确定 sink 的类型
| 常使用的类型有: |
| 1) avro: 用于输出到下一个Flume Agent ,一个开源的序列化框架 |
| 2) hdfs: 输出到hdfs |
| 3) fill_roll: 输出到本地 |
| 4) logger: 输出到控制台 |
| 5) hbase: 输出到hbase |
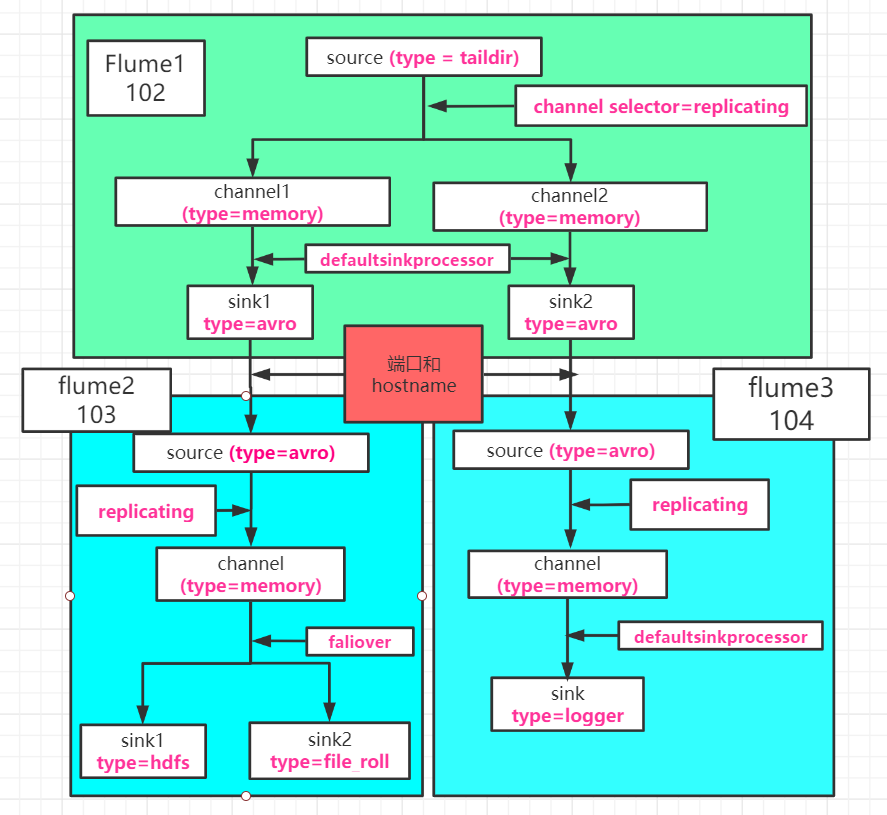
# 1.1.6 拓扑例图
![图3]()
图 3
# 1.2 写配置文件
# 1.2.1 配置文件的构成
- Name the components on this agent -- agent Name
- Describe/configure the source -- source
- channel selector
- Describe the channel -- channel
- sinkprocessor
- Describe the sink --sink
- Bind the source and sink to the channel -- 连接 source、channel、sink
# 1.2.2 agent Name
情况 1:source、channel、sink 各一个
| a1.sources = r1 |
| a1.sinks = k1 |
| a1.channels = c1 |
情况 2:source 一个、channel 一个、sink 多个
| a1.sources = r1 |
| a1.channels = c1 |
| a1.sinkgroups = g1 |
| a1.sinks = k1 k2 |
情况 3:source 一个、channel 多个、sink 多个
| a1.sources = r1 |
| a1.sinks = k1 k2 |
| a1.channels = c1 c2 |
# 1.2.3 source
情况 1:avro
| a1.sources.r1.type = avro |
| a1.sources.r1.bind = hadoop102 |
| a1.sources.r1.port = 4141 |
情况 2:netcat
| a1.sources.r1.type = netcat |
| a1.sources.r1.bind = localhost |
| a1.sources.r1.port = 44444 |
情况 3:exec
| a1.sources.r1.type = exec |
| a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log |
| a1.sources.r1.shell = /bin/bash -c |
情况 4: sqooldir
| |
| a1.sources.r1.type = spooldir |
| a1.sources.r1.spoolDir = /opt/module/flume/upload |
| a1.sources.r1.fileSuffix = .COMPLETED |
| a1.sources.r1.fileHeader = true |
| |
| a1.sources.r1.ignorePattern = ([^ ]*\.tmp) |
情况 5:talidir
| |
| a1.sources.r1.type = TAILDIR |
| a1.sources.r1.positionFile = /opt/module/flume/tail_dir.json |
| a1.sources.r1.batchSize=500 |
| a1.sources.r1.filegroups = f1 f2 |
| a1.sources.r1.filegroups.f1 = /opt/module/flume/files/.*file.* |
| a1.sources.r1.filegroups.f2 = /opt/module/flume/files/.*log.* |
# 1.2.4 channel selector
情况 1: replicating channel selector
# 将数据流复制给所有channel
a1.sources.r1.selector.type = replicating
情况 2:multiplexing channel selector 需配合指定的拦截器使用(interceptor)
| |
| a1.sources.r1.interceptors = i1 |
| a1.sources.r1.interceptors.i1.type = com.miyazono.flume.interceptor.CustomInterceptor$Builder |
| |
| |
| |
| a1.sources.r1.selector.type = multiplexing |
| a1.sources.r1.selector.header = type |
| a1.sources.r1.selector.mapping.letter = c1 |
| a1.sources.r1.selector.mapping.number = c2 |
# 1.2.5 channel
情况 1: memory
| |
| a1.channels.c1.type = memory |
| a1.channels.c1.capacity = 1000 |
| a1.channels.c1.transactionCapacity = 100 |
情况 2 : flie
| a1.channels.c1.type=file |
| a1.channels.c1.checkpointDir=/opt/module/flume/checkpoint/behavior1 |
| a1.channels.c1.dataDirs=/opt/module/flume/data/behavior1/ |
| a1.channels.c1.capacity=1000000 |
| a1.channels.c1.maxFileSize=2146435071 |
| a1.channels.c1.keep-alive=6 |
# 1.2.6 sinkprocessor
情况 1:DefaultSinkProcessor -- 对应单个 Sink
不用写任何配置信息,默认值。
情况 2:FailoverSinkProcessor -- 对应的是 Sink Group
| a1.sinkgroups.g1.processor.type = failover |
| a1.sinkgroups.g1.processor.priority.k1 = 5 |
| a1.sinkgroups.g1.processor.priority.k2 = 10 |
| a1.sinkgroups.g1.processor.maxpenalty = 10000 |
情况 3:LoadBalancingSinkProcessor -- 对应的是 Sink Group
| a1.sinkgroups.g1.processor.type =load_balance |
| a1.sinkgroups.g1.processor.backoff = true |
| a1.sinkgroups.g1.processor.selector =round_robin |
# 1.2.7 sink
情况 1:avro
| |
| a1.sinks.k1.type = avro |
| a1.sinks.k1.hostname = hadoop104 |
| a1.sinks.k1.port = 4141 |
情况 2:hdfs
| a1.sinks.k1.type = hdfs |
| a1.sinks.k1.hdfs.path = hdfs: |
| |
| a1.sinks.k1.hdfs.filePrefix = upload- |
| |
| a1.sinks.k1.hdfs.round = true |
| |
| a1.sinks.k1.hdfs.roundValue = 1 |
| |
| a1.sinks.k1.hdfs.roundUnit = hour |
| |
| a1.sinks.k1.hdfs.useLocalTimeStamp = true |
| |
| a1.sinks.k1.hdfs.batchSize = 100 |
| |
| a1.sinks.k1.hdfs.fileType = DataStream |
| |
| a1.sinks.k1.hdfs.rollInterval = 60 |
| |
| a1.sinks.k1.hdfs.rollSize = 134217700 |
| |
| a1.sinks.k1.hdfs.rollCount = 0 |
情况 3:fill_roll
| |
| a1.sinks.k1.type = file_roll |
| a1.sinks.k1.sink.directory = /opt/module/flume/datas/flume3 |
情况 4:logger
| |
| a1.sinks.k1.type = logger |
情况 5:hbase --- 暂时不讨论
# 1.2.8 连接 source、channel、sink
情况 1:source、channel、sink 各一个、
| a1.sources.r1.channels = c1 |
| a1.sinks.k1.channel = c1 |
情况 2:source 一个、channel 一个、sink 多个
| |
| a1.sources.r1.channels = c1 |
| a1.sinkgroups.g1.sinks = k1 k2 |
| a1.sinks.k1.channel = c1 |
| a1.sinks.k2.channel = c1 |
情况 3:source 一个、channel 多个、sink 多个
| |
| a1.sources.r1.channels = c1 c2 |
| a1.sinks.k1.channel = c1 |
| a1.sinks.k2.channel = c2 |
# 1.2.9 端口和 ip 的区别
- source 端:监视指定端口并接收指定 ip 发送来的数据
| 端口:该端口只能是自己机器的端口 |
| ip(hostname):指能够接受来自此ip的数据 |
# 1.3 连接 flume
# 1.3.1 查看指定 ip 的通信端口
sudo netstat -ntlp | grep 端口号
# 1.3.2 关闭端口
sudo kill 端口的进程号
# 1.3.3 连接指定 ip 地址的指定端口
nc ip 端口号
# 1.3.4 启动 flume
| bin/flume-ng agent -n [agent name] -c conf -f [自定义flume配置文件] -Dflume.root.logger=INFO,console |
# 二、自定义 interceptor,source、 sink
# 2.1 自定义 intercepor
| package flume_interceptor; |
| |
| import org.apache.flume.Context; |
| import org.apache.flume.Event; |
| import org.apache.flume.interceptor.Interceptor; |
| |
| import java.util.List; |
| import java.util.Map; |
| |
| |
| * @author lianzhipeng |
| * @Description |
| * @create 2020-05-05 10:45 |
| */ |
| |
| public class MyInterceptor implements Interceptor { |
| |
| |
| * Description: 初始化方法,新建 Interceptor 时使用 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 10:45 |
| * @return: void |
| */ |
| public void initialize() { |
| |
| } |
| |
| |
| * Description: 更改方法,对 event 进行处理 |
| * |
| * @param event 传入的数据 |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 10:47 |
| * @return: org.apache.flume.Event 返回处理好的数据 |
| */ |
| public Event intercept(Event event) { |
| |
| |
| Map<String, String> headers = event.getHeaders(); |
| |
| |
| |
| byte[] body = event.getBody(); |
| |
| |
| |
| String string = new String(body); |
| char c = string.charAt(0); |
| |
| if (c >= 'a' && c <= 'z' || c >= 'A' && c <= 'Z') { |
| headers.put("type", "char"); |
| } else { |
| headers.put("type", "not-char"); |
| } |
| |
| |
| |
| return event; |
| |
| |
| } |
| |
| public List<Event> intercept(List<Event> list) { |
| |
| for (Event event : list) { |
| intercept(event); |
| } |
| return list; |
| |
| |
| } |
| |
| public void close() { |
| |
| } |
| |
| |
| * 框架会调用 MyBulider 来创建自定义拦截器实例 |
| */ |
| public static class MyBulider implements Builder { |
| |
| |
| * Description: 创建自定义拦截器实例的方法 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 10:54 |
| * @return: org.apache.flume.interceptor.Interceptor |
| */ |
| public Interceptor build() { |
| return new MyInterceptor(); |
| } |
| |
| |
| * Description: 读取配置信息 |
| * |
| * @param context |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 10:54 |
| * @return: void |
| */ |
| public void configure(Context context) { |
| |
| } |
| } |
| } |
# 2.2 自定义 source
| package flume_interceptor; |
| |
| import org.apache.flume.Context; |
| import org.apache.flume.Event; |
| import org.apache.flume.EventDeliveryException; |
| import org.apache.flume.PollableSource; |
| import org.apache.flume.channel.ChannelProcessor; |
| import org.apache.flume.conf.Configurable; |
| import org.apache.flume.event.SimpleEvent; |
| import org.apache.flume.source.AbstractSource; |
| |
| |
| * @author lianzhipeng |
| * @Description |
| * @create 2020-05-05 14:31 |
| */ |
| |
| public class MySource extends AbstractSource implements Configurable, PollableSource { |
| private String prefix; |
| private Long interval; |
| |
| |
| |
| * Description: 拉取事件并交给 ChannelProcessor 处理的方法 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 14:33 |
| * @return: org.apache.flume.PollableSource.Status |
| */ |
| public Status process() throws EventDeliveryException { |
| Status status = null; |
| |
| try { |
| |
| Event e = getSomeData(); |
| |
| |
| ChannelProcessor channelProcessor = getChannelProcessor(); |
| |
| channelProcessor.processEvent(e); |
| |
| status = Status.READY; |
| } catch (Throwable t) { |
| |
| |
| status = Status.BACKOFF; |
| |
| |
| if (t instanceof Error) { |
| throw (Error)t; |
| } |
| } |
| |
| return status; |
| } |
| |
| |
| |
| * Description: 拉取数据并包装成 event 的过程 |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 14:55 |
| * @return: org.apache.flume.Event 拉取到的数据 |
| */ |
| private Event getSomeData() throws InterruptedException { |
| |
| int i = (int) (Math.random() * 1000); |
| |
| |
| String message = prefix + i ; |
| |
| Thread.sleep(interval); |
| |
| SimpleEvent event = new SimpleEvent(); |
| |
| event.setBody(message.getBytes()); |
| return event; |
| |
| } |
| |
| * Description: 如果拉取不到数据,backoff 时间的增长速度 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 14:34 |
| * @return: long 增长量 |
| */ |
| public long getBackOffSleepIncrement() { |
| return 1000; |
| } |
| |
| |
| * Description: 最大的等待时间 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 14:38 |
| * @return: long |
| */ |
| public long getMaxBackOffSleepInterval() { |
| return 10000; |
| } |
| |
| |
| * Description: 配置参数,来自于 configurable,可以定义我们自己定义的 source |
| * |
| * @param context 配置文件 |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 14:39 |
| * @return: void |
| */ |
| public void configure(Context context) { |
| |
| prefix = context.getString("prefff","xxxx" ); |
| interval = context.getLong("interval",500L); |
| |
| } |
| } |
# 2.3 自定义 sink
| package flume_interceptor; |
| |
| import org.apache.flume.*; |
| import org.apache.flume.conf.Configurable; |
| import org.apache.flume.sink.AbstractSink; |
| |
| import java.io.IOException; |
| |
| |
| * @author lianzhipeng |
| * @Description |
| * @create 2020-05-05 14:31 |
| */ |
| |
| public class MySiink extends AbstractSink implements Configurable { |
| |
| * Description: 改方法调用时,会从 Channel 中拉取数据并处理 |
| * |
| * @Author: lianzhipeng |
| * @Date: 2020/5/5 15:09 |
| * @return: org.apache.flume.Sink.Status 处理的状态 |
| */ |
| public Status process() throws EventDeliveryException { |
| Status status = null; |
| |
| |
| |
| Channel ch = getChannel(); |
| |
| Transaction txn = ch.getTransaction(); |
| |
| txn.begin(); |
| try { |
| |
| |
| |
| Event event; |
| |
| while ((event = ch.take()) == null) { |
| Thread.sleep(100); |
| } |
| |
| |
| |
| storeSomeData(event); |
| |
| txn.commit(); |
| status = Status.READY; |
| } catch (Throwable t) { |
| txn.rollback(); |
| |
| |
| |
| status = Status.BACKOFF; |
| |
| |
| if (t instanceof Error) { |
| throw (Error) t; |
| } |
| } finally { |
| |
| txn.close(); |
| } |
| return status; |
| } |
| |
| private void storeSomeData(Event event) throws IOException { |
| |
| |
| byte[] body = event.getBody(); |
| |
| System.out.write(body); |
| System.out.println(); |
| } |
| |
| |
| public void configure(Context context) { |
| |
| } |
| } |
# 三、kafka 与 flume 的结合
kafka:数据的中转站,主要功能由 topic 体现;
flume:数据的采集,通过 source 和 sink 体现。
# 3.1 kafka source
配置文件:
| a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource |
| a1.sources.r1.kafka.bootstrap.servers = hadoop105:9092,hadoop106:9092 |
| a1.sources.r1.kafka.topics=topic_log |
| a1.sources.r1.batchSize=6000 |
| a1.sources.r1.batchDurationMillis=2000 |
# 3.2 kakfa channel
- kakfa channel 这种情况使用的最多,此时的 flume 可以是消费者、生产者、source 和 sink 之间的缓冲区(具有高吞吐量的优势),Channel 是位于 Source 和 Sink 之间的缓冲区。
- 一共有三种情况,分别是:
| |
| kakfa channel为事件提供了可靠且高可用的通道; |
| |
| |
| it allows writing Flume events into a Kafka topic, for use by other app |
| |
| |
| it is a low-latency, fault tolerant way to send events from Kafka to Flume sinks such as HDFS, HBase or Solr |
配置文件:
| a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel |
| a1.channels.c1.kafka.bootstrap.servers = hadoop105:9092,hadoop106:9092,hadoop107:9092 |
| a1.channels.c1.kafka.topic =topic_log |
| a1.channels.c1.parseAsFlumeEvent=false |
# 3.3 kafka sink
作用:将数据拉取到 kafka 的 topic 中。
配置文件:
| a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink |
| a1.sinks.k1.kafka.topic =topic_log |
| a1.sinks.k1.kafka.bootstrap.servers = hadoop105:9092,hadoop106:9092,hadoop107:9092 |
| a1.sinks.k1.kafka.flumeBatchSize = 20 |
| a1.sinks.k1.kafka.producer.acks = 1 |
| a1.sinks.k1.kafka.producer.linger.ms = 1 |
| a1.sinks.k1.kafka.producer.compression.type = snappy |